Exploring AI with Node.js
Chances are JavaScript isn't the first language that pops into your head when you think of AI — that honour usually goes to Python. But as with many technologies, what starts elsewhere often finds its way to JavaScript. And AI is no exception. Thanks to some powerful libraries, Node.js can be a great alternative for building AI applications, achieving results comparable to those of Python.
I've been really into the AI boom lately. Using tools like GitHub Copilot and ChatGPT has made my work better and faster. I've learned much about best practices and new ways to tackle problems. It's been a real eye-opener.
This growing interest led me to experiment with what I could create using today's available technologies, such as the OpenAI API and AI models that can be used offline. So, I put together a Proof of Concept (POC), which aimed to create a fundamental building block for future projects where only the imagination is the limit.
Project overview
I will not get too technical in this article. Instead, I will provide a high-level overview of the project and the technologies used. The goal is to show the POC's results and capabilities and then let your imagination run wild with the possibilities of what it could be used for.
For this POC, I've chosen to work with Node.js, Express, and TypeScript. To make things easier, I've also included libraries such as LangChain.js, a framework for developing applications powered by language models, and ChromaDB, an AI-native open-source vector database.
The goal of the Proof of Concept (POC) is to demonstrate the following capabilities:
Integration with OpenAI API
The application should be capable of generating responses using the OpenAI API. This is a good way to get started with AI, as it's easy to use and provides a lot of value. The OpenAI API is a paid service, but it offers the best AI models available today and is straightforward to use.
Local AI model implementation
Besides the OpenAI API, we want to incorporate a "local" AI. This means using an AI model that is downloaded and runs entirely offline on my computer. This is useful when you want to keep your data private and/or don't want to pay for the OpenAI API.
Question and answer system
The system should be able to handle a simple question-and-answer scenario. Users should be able to ask questions and receive contextually relevant answers. For example, if the user asks, "Who won the Super Bowl in 2020?" the system should be able to provide the correct answer.
Dynamic JSON object creation
The system should generate a pre-defined JSON object based on specific instructions. Each field in this object will be populated following distinct guidelines. Here's an example of generating a person object:
const OUTPUT_SCHEMA = z.object({
name: z.string().describe("Human name"),
surname: z.string().describe("Human surname"),
age: z.number().describe("Human age"),
appearance: z.string().describe("Human appearance description"),
shortBio: z.string().describe("Short bio description"),
university: z.string().optional().describe("University name if attended"),
gender: z.string().describe("Gender of the human"),
interests: z
.array(z.string())
.describe("json array of strings human interests"),
});
With a simple prompt like "A person in Denmark", the returned result should be a generic Danish person (stereotypes included) based on those fields.
Vector database utilisation
A key part of this POC is to use a vector database (which runs locally). This database will help the AI learn information unknown to it. For instance, in this project, I will feed the AI a PDF document from a Wikipedia page detailing the winner of the Super Bowl 2023. This event is (at the time of writing) unknown to the AI models I plan to use. The AI should be able to process this information, accurately inform me about the Super Bowl winner, and provide details about the game.
The OpenAI API

In this POC, I'm using the GPT-3.5 Turbo model. This model is better than the previous GPT-3 model but not as good as the GPT-4 model, which most people are familiar with when using ChatGPT. But GPT-3.5 Turbo is cheap and it works for most use cases.
Question and answer system
A lot of people have already used the OpenAI API in some form and know what to expect. For this project, I am using it as a reference point for the local AI model.
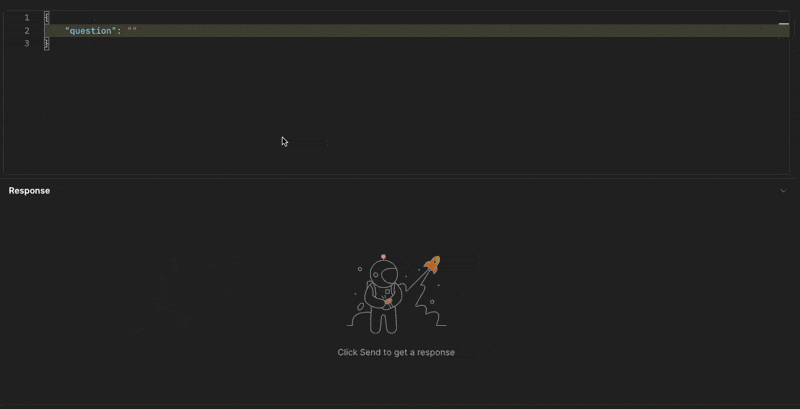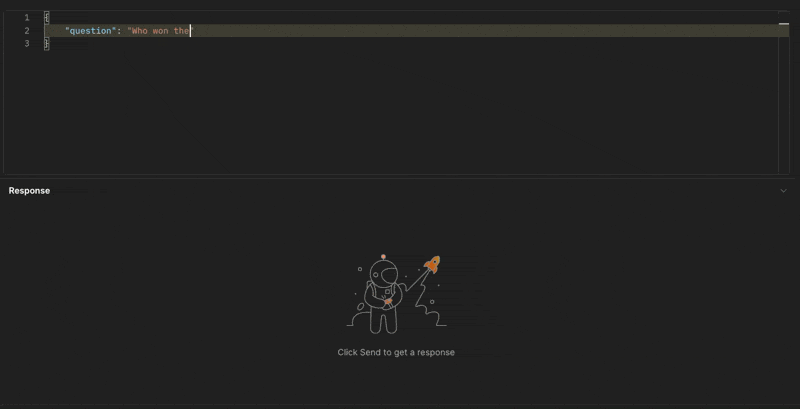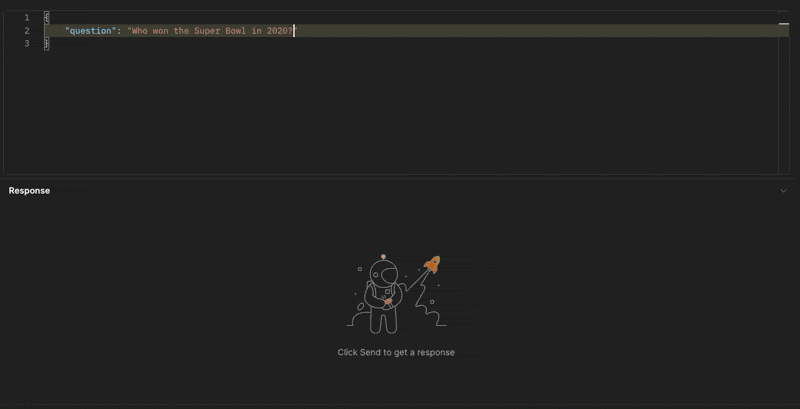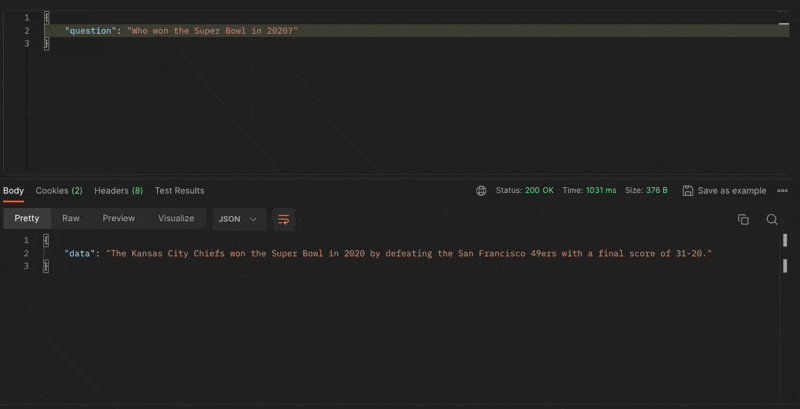
I'm asking the OpenAI API about the 2020 Super Bowl. The response is as follows:
{
"data": "The Kansas City Chiefs won the Super Bowl in 2020 by defeating the San Francisco 49ers with a final score of 31-20."
}
The response is insantaneous and accurate. A great start!
Dynamic JSON object creation
Using the previously mentioned schema, I can generate a person object with the following prompt: "A person in Denmark".
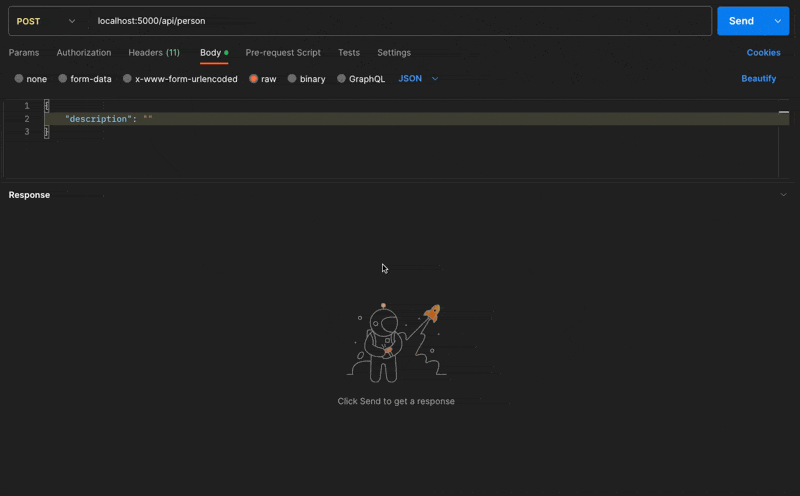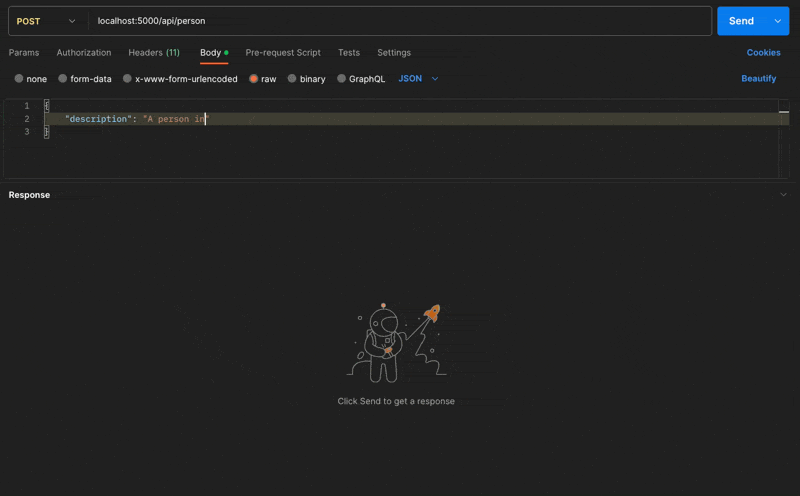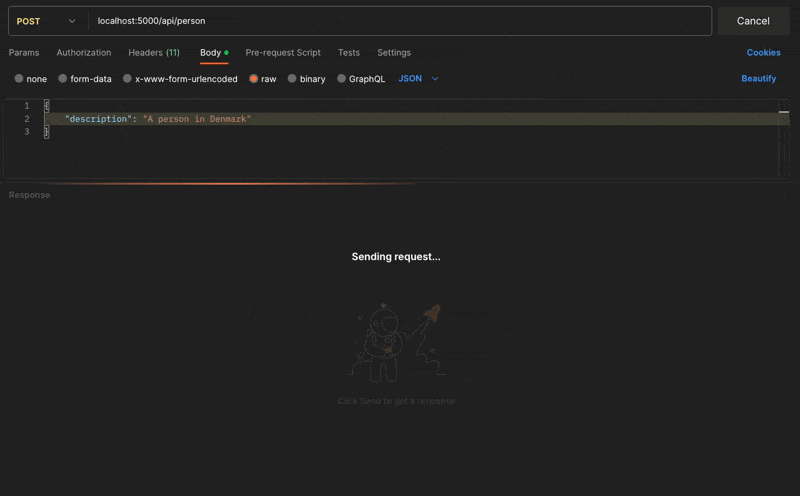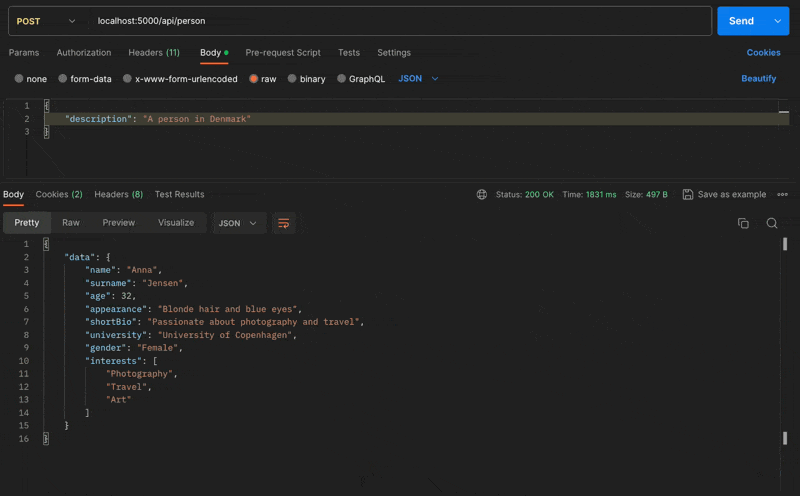
The response is as follows:
{
"data": {
"name": "Anna",
"surname": "Jensen",
"age": 32,
"appearance": "Blonde hair and blue eyes",
"shortBio": "Passionate about photography and travel",
"university": "University of Copenhagen",
"gender": "Female",
"interests": ["Photography", "Travel", "Art"]
}
}
The data generated is quite generic, which is expected given the generic prompt and schema (garbage in, garbage out). However, the goal is to demonstrate the capability of generating a JSON object based on specific instructions.
Vector database utilisation
I start by downloading the Wikipedia page as a PDF document detailing the Super Bowl 2023 game (referenced as Super Bowl LVII or the 2022 season). I then upload the document to the vector database.
After adding the document to the vector database, I can quickly query it to see if it's been added correctly.
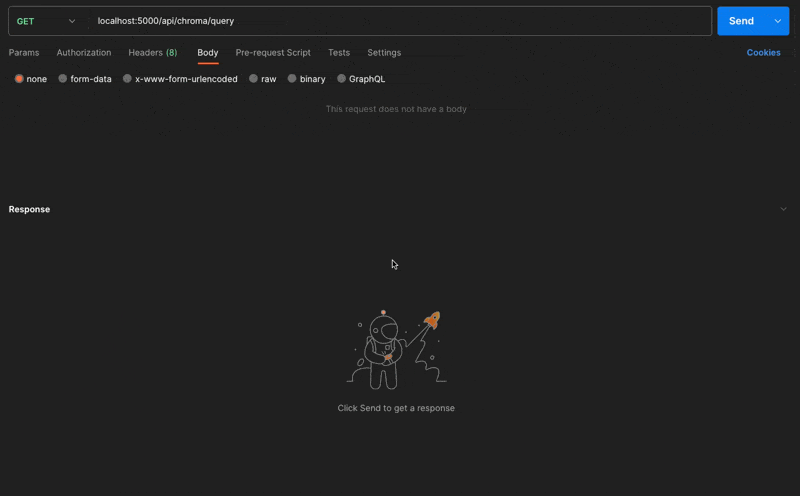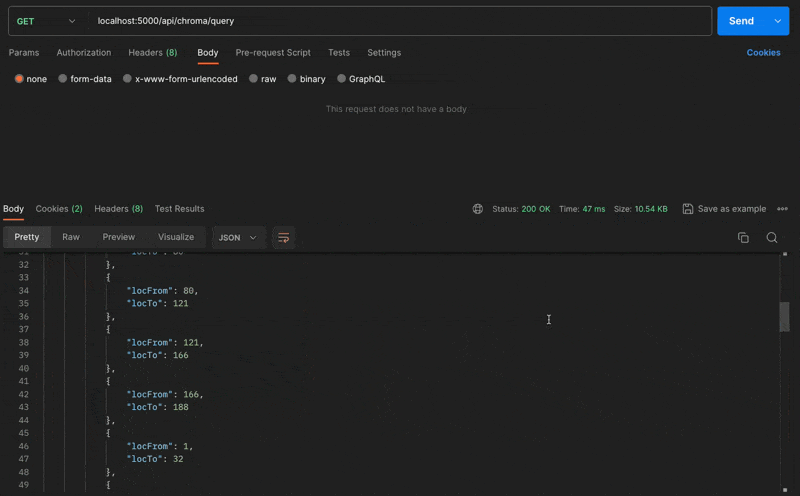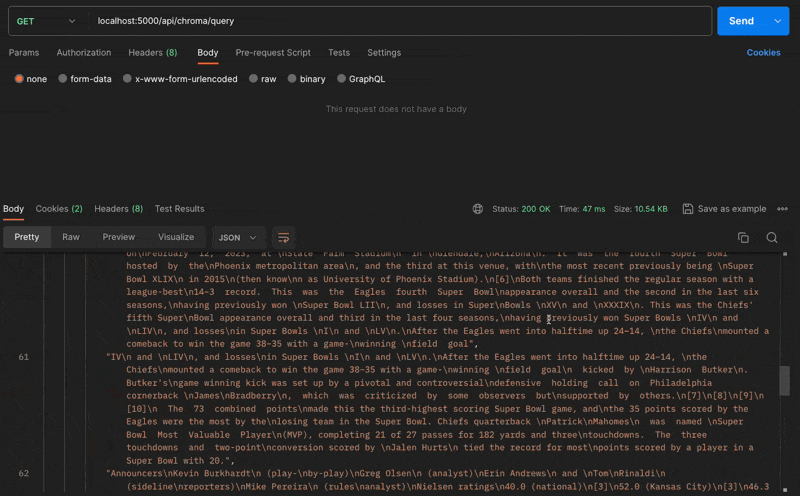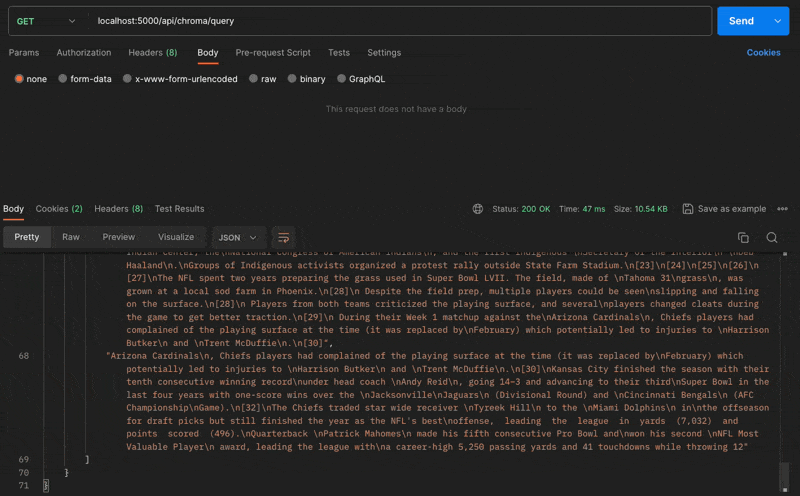
The document has been successfully added as a vector. The AI should now be able to answer questions about Super Bowl 2023.

The response is as follows:
{
"data": {
"text": "The Kansas City Chiefs won Super Bowl LVII for the 2022 season, defeating the Philadelphia Eagles with a score of 38-35. The game was played on February 12, 2023, at State Farm Stadium in Glendale, Arizona. Patrick Mahomes was awarded the MVP. The halftime show featured Rihanna and the game was broadcast on Fox."
}
}
Let's see if the OpenAI API can provide the same answer without adding the document to the vector database.
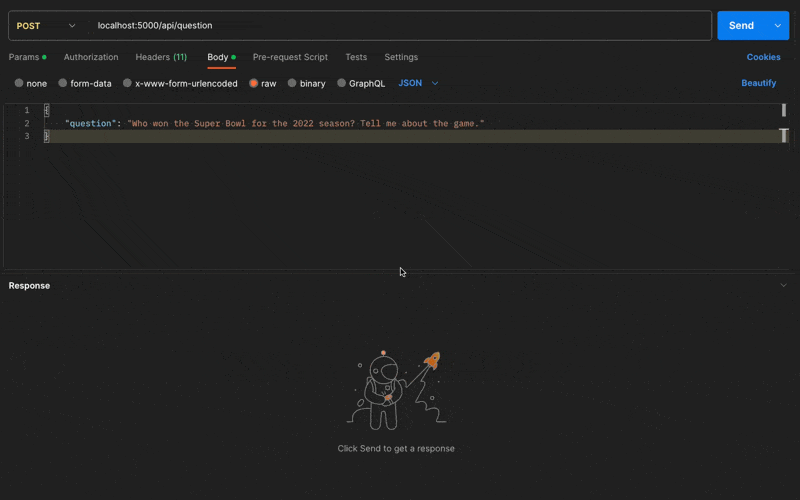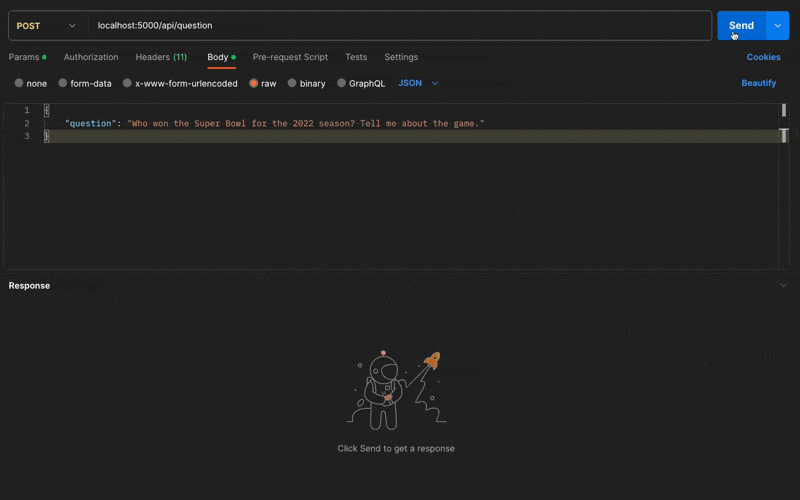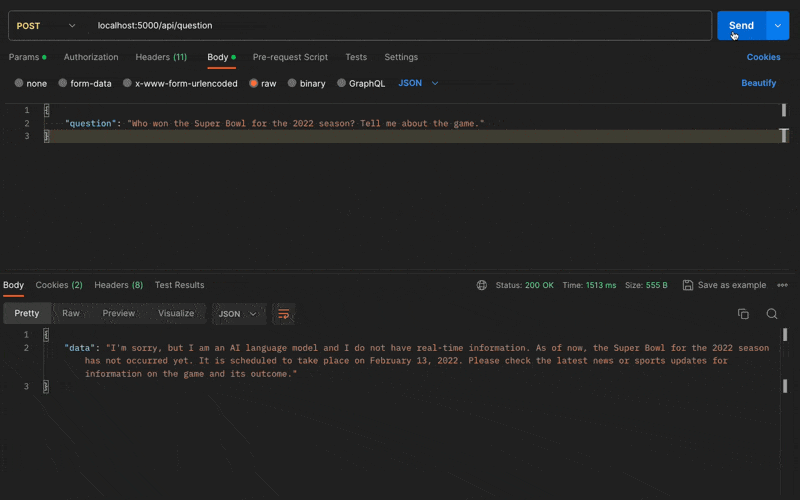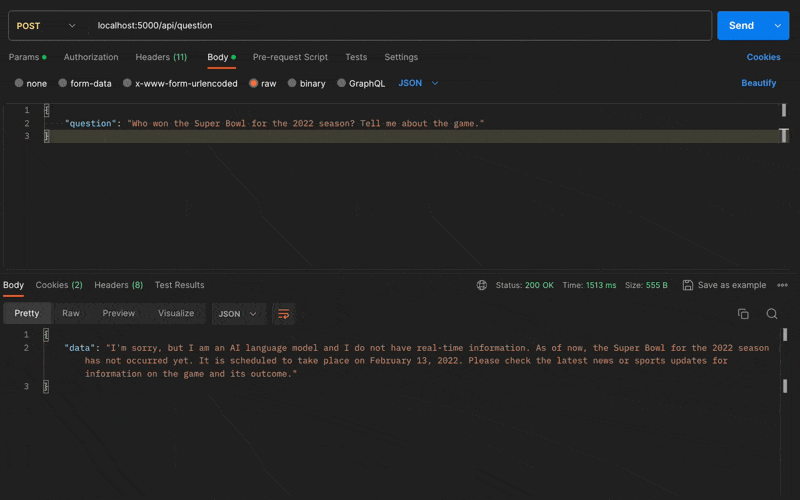
As expected, the OpenAI API doesn't know the answer:
{
"data": "I'm sorry, but I am an AI language model and I do not have real-time information. As of now, the Super Bowl for the 2022 season has not occurred yet. It is scheduled to take place on February 13, 2022. Please check the latest news or sports updates for information on the game and its outcome."
}
This concludes the OpenAI API section. The next step is to implement a local AI model.
Local AI model
There are tons of AI models available today, but for this project, I've chosen to use the open-source GPT4All model. The model is downloaded and runs entirely offline on my computer. It can't compete with the OpenAI API, but open-source models are improving daily. The difference might be negligible in a year from now (or even sooner).
Since it's running on my MacBook Pro, the response time will be slower than the OpenAI API. In a real production environment, you would run the model on a server with more resources, and the response time would be much faster.
Question and answer system
I ask the local AI model the same question as before: "Who won the Super Bowl in 2020?".
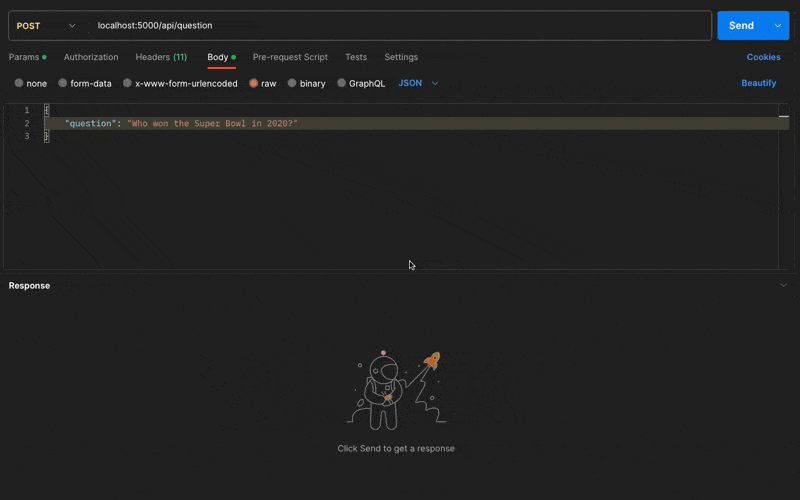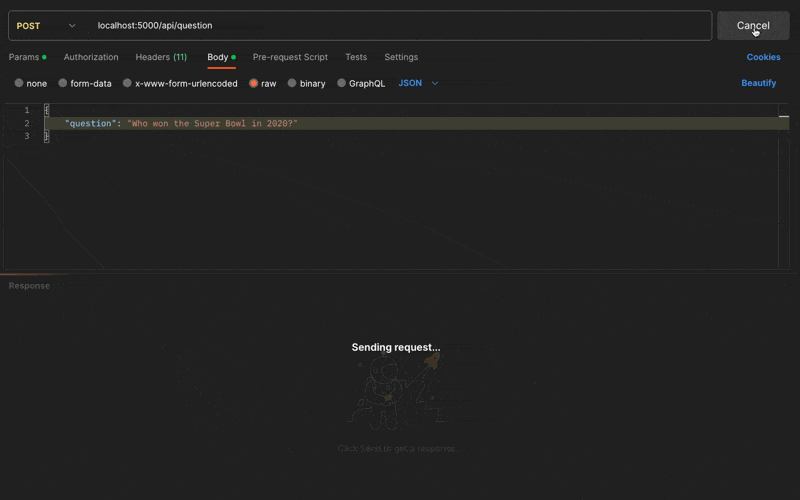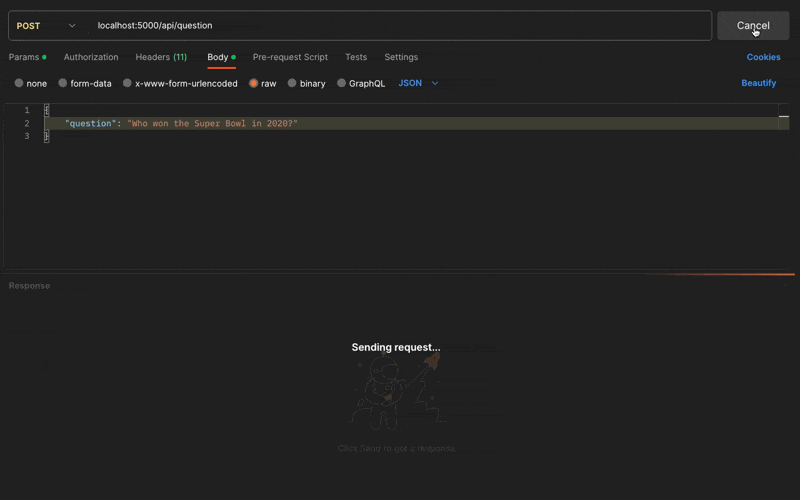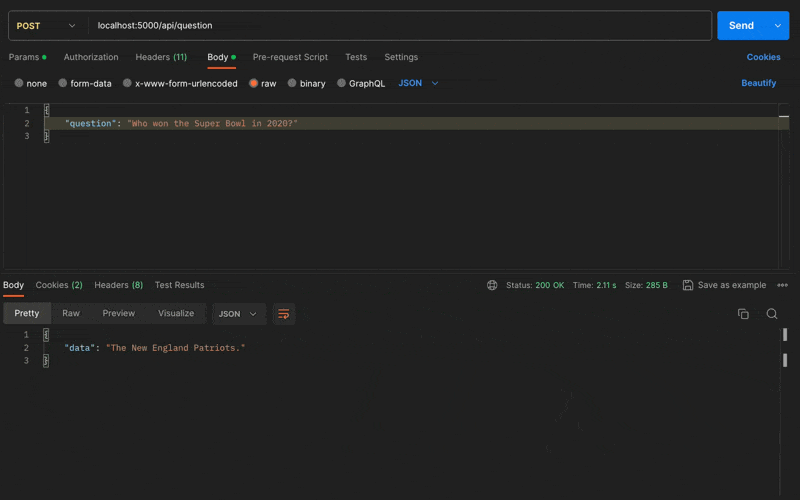
The response is as follows:
{
"data": "The New England Patriots."
}
The response is incorrect. This is not unexpected since we don't know what the model has been trained on. Clearly, the model needs more training data to answer this question correctly, but we can see the early potential of it.
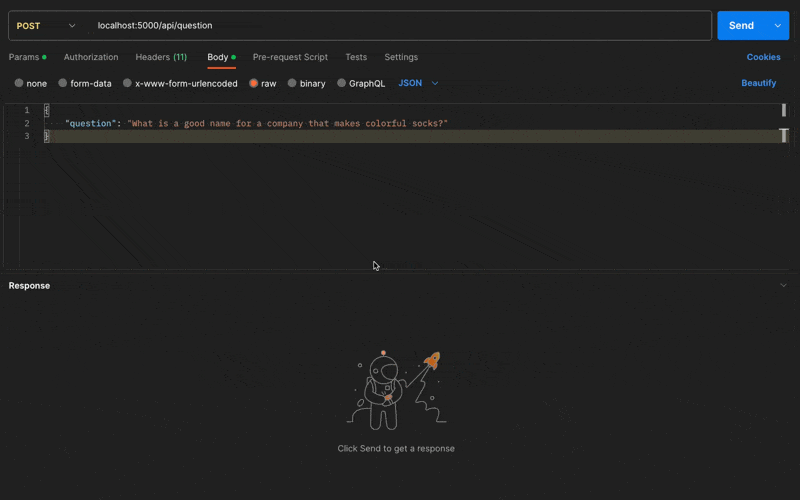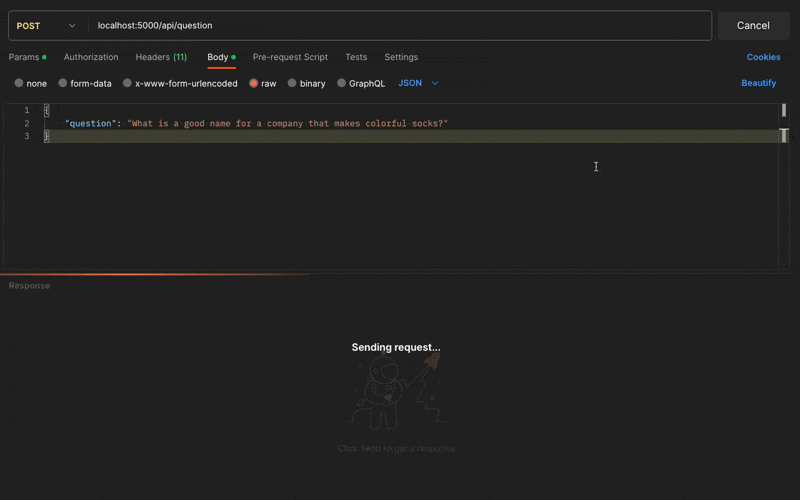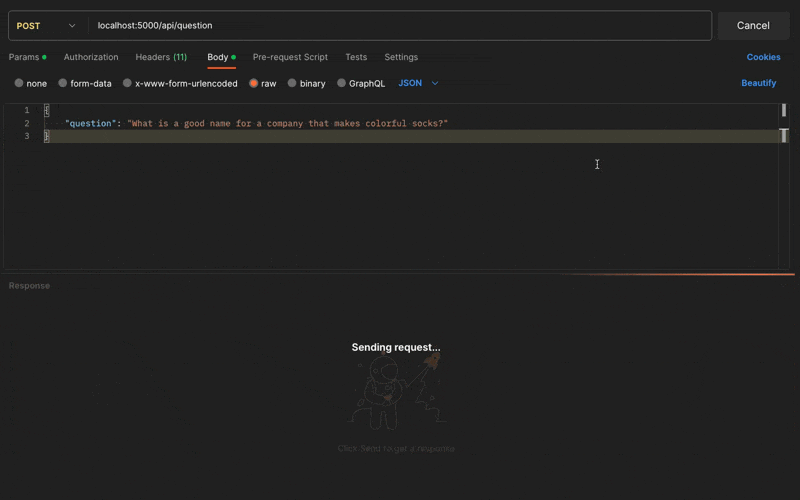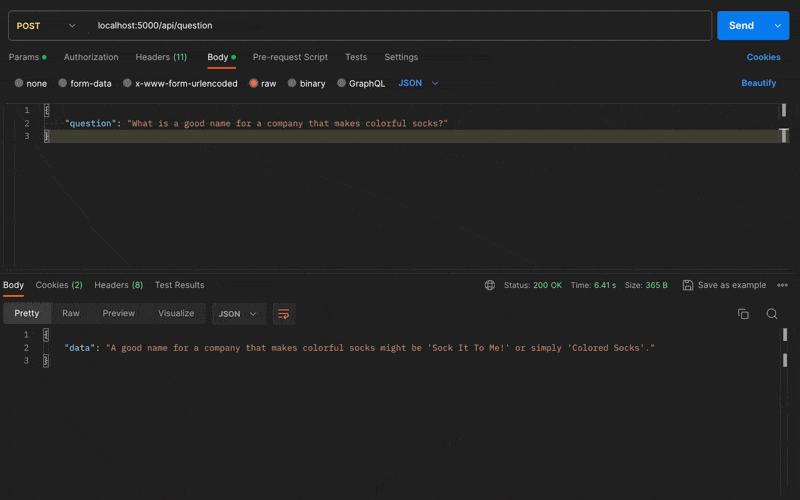
Let's try a different use case. I want to see what it can generate based on its imagination. I prompt the AI: "What is a good name for a company that makes colorful socks?".
The response is as follows:
{
"data": "A good name for a company that makes colorful socks might be 'Sock It To Me!' or simply 'Colored Socks'."
}
The response is quite good. It's creative and fits the prompt. We can tinker with the temperature setting, which can be between 0 and 1, where 0 is the most conservative, and 1 is the most creative. If I set the temperature to 1, the response might be more creative and unpredictable. When trying the same prompt with a temperature of 1, the response is as follows:
{
"data": "A good name for a company that makes colorful socks could be 'Bunny Socks Factory'."
}
Similarly, if I set the temperature to 0.1, the response is as follows:
{
"data": "A good name for a company that makes colorful socks might be 'Colorful Socks Inc.'."
}
Personally, I prefer "Bunny Socks Factory" here 🐰
Dynamic JSON object creation
I prompt the model: "A person in Denmark".
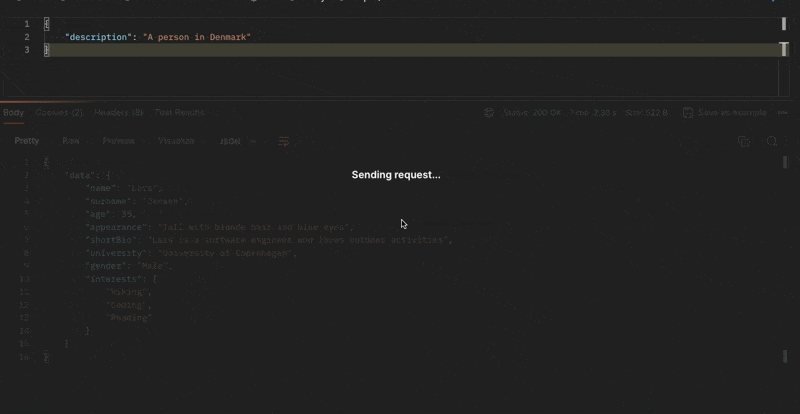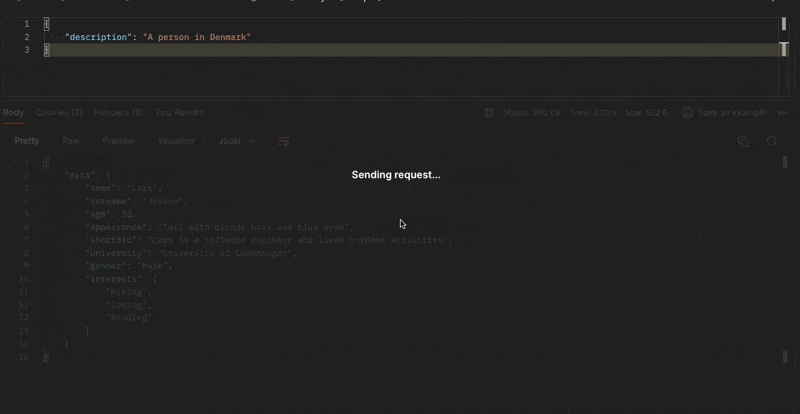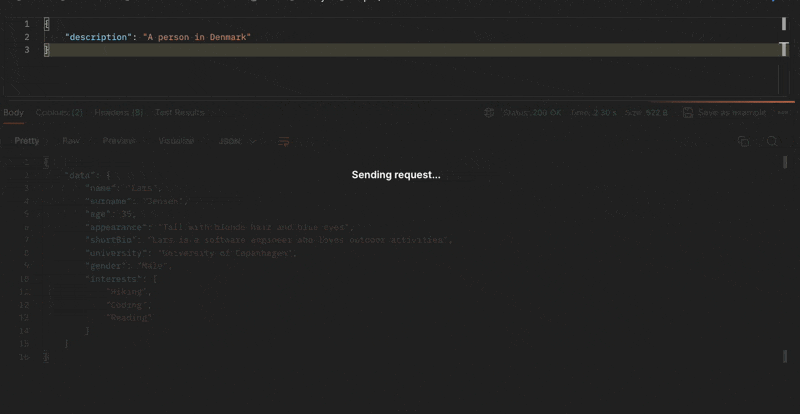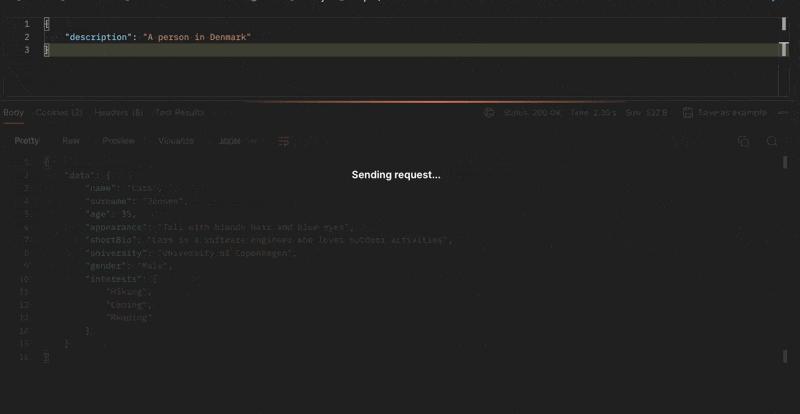
This time, the CPU usage went through the roof. After 10 minutes, I had to stop the process. My poor MacBook couldn't handle the load generated by the model. It's unfortunate, but it's a good example of why you should run the model on a server with more resources.
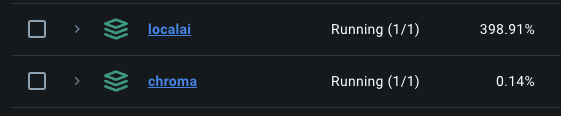
Vector database utilisation
The uploaded document we used before is still in the vector database. All we have to change is the endpoint to query the local AI model instead of the OpenAI API.
The load time is again quite high, but eventually, the response is as follows:
{
"data": {
"text": "The Kansas City Chiefs won the 2022 Super Bowl (Super Bowl LVII) by defeating the Philadelphia Eagles. The final score was 38-35 in favor of the Chiefs."
}
}
The data generated is quite similar to the previous response from the OpenAI API. The only real difference was the load time and the details in the response.
Conclusion
OpenAI still has the upper hand in the AI space, but local AI models are catching up quickly. The GPT4All model I used in this project is just one of many available today, and more are being developed daily. The potential for local AI models is enormous; you only need the proper hardware to run them and the correct data to train them.
Even though the local AI models can't compete with OpenAI, it's a safe bet that they will be on par in the near future. Any company should start considering building the infrastructure needed to run these models locally. The benefits are clear: you own the data, you control the model, and you can train it on your data. Swapping out the model is easy if a better one comes along.
I believe open-source models will overtake proprietary ones very soon. The quality of open-source models is improving rapidly since more people are contributing. The more people contribute, the faster the models improve. And companies prefer open-source models because they are cost-effective, private, and adaptable.
One open-source model I would keep an eye on is Llama. It's run by Meta (formerly Facebook) and is a direct competitor to GPT-4. It recently released its Llama 2 model with 70B parameters. It's a beast of a model and free to use.
When I started diving into AI, it was overwhelming, to say the least. There is so much to learn and so many tools to choose from. And it's not an overstatement to say that the landscape changes weekly. But it's a lot of fun once you get the hang of things. To generate things out of thin air and see what the AI comes up with is fascinating.
One challenge I see as a non-native English speaker is the lack of models in other languages. Most models are trained on English data, and only a fraction are trained in other languages. I hope to see future models supporting more languages. The world is not only English-speaking, and the AI models should reflect that.
Edit: After writing this article, AI Sweden released a model intended for the Nordic languages called GPT-SW3, which is a significant step in the right direction.